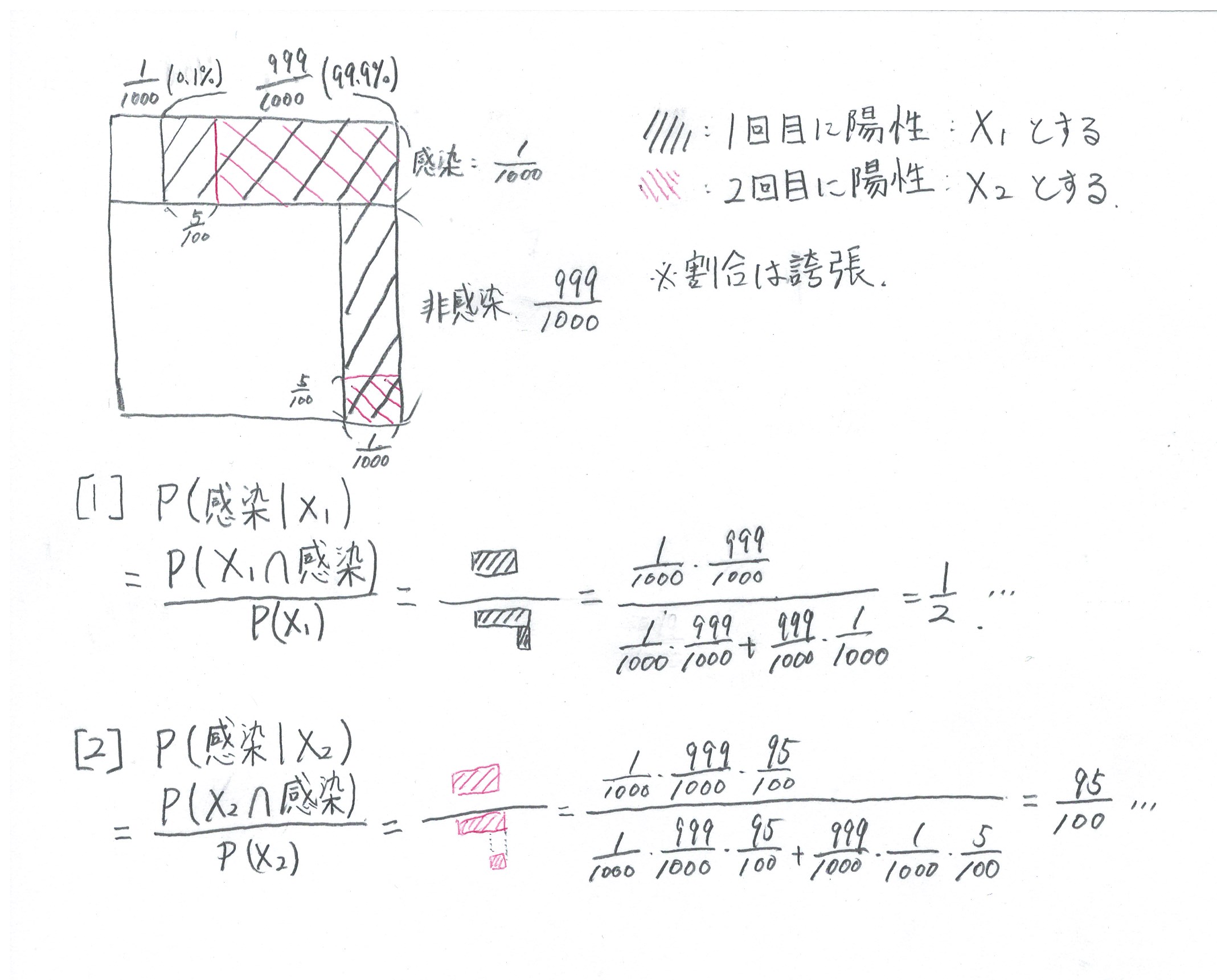
問1 ベイズの定理

ベイズの定理に従って分解していくことも可能だが、ミスが起こりやすいので個人的には好きじゃない。
問2 期待値、分散の性質
[1]
$$E[X^2_i]=0^2\cdot P(X_i=0)+1^2\cdot P(X_i=1)=0+1\cdot\frac{1}{2}$$
[2]
$$E[X_iX_j]=0\cdot 0P(X_i=0\cap X_j=0)+0\cdot 1P(X_i=0\cap X_j=1)$$
$$+1\cdot 0P(X_i=1\cap X_j=0)+1\cdot 1P(X_i=1\cap X_j=1)$$
$$=0+0+0+1\cdot \frac{1}{2}\cdot \frac{4}{9}=\frac{2}{9}$$
[3]
$$X_iがi.i.dじゃないことに注意すると、$$
$$V[\bar{X}]=V[\frac{1}{5}\sum^5_{i=1}X_i]=\frac{1}{25}V[X_1+X_2+X_3+X_4+X_5]$$
$$=\frac{1}{25}\begin{pmatrix}5V[X_i]+2\cdot _5C_2Cov[X_iX_j]\end{pmatrix}\tag{1}$$
$$V[X_i]=E[X_i^2]-(E[x_i])^2=\frac{1}{4}$$
$$Cov(X_iX_j)=E[X_iX_j]-E[X_i]E[X_j]=\frac{2}{9}-\frac{1}{4}$$
これらを(1)式へ代入して、
$$V[\bar{X}]=\frac{1}{36}$$
を得る。
問4 検定
[1]
これを間違えるときはケアレスミスが中心になると思う。
選択肢のグラフに合わせてクロス集計表を見直して、
20代女
$$利用:非利用=60:46\simeq 4:3$$
20代男
$$利用:非利用=38:73\simeq 1:2$$
と考えれば見やすいのでケアレスミス対策になると思う。
答えは①
[2]
集計自体が「利用する」と「利用しない」の二択だし二項分布を連想する。
で、利用”率”の差という話も出ているし、かの有名な母比率の差の標準化式を探せばいい。
答えは①
ちなみに、
③はカイ二乗適合度検定に使う検定統計量
④はOR(オッズ比)が絡むときの検定統計量
⑤は分割表のピアソンのカイ二乗統計量
問5 ノンパラメトリック
[1]
問題の指示通りに数字の小さい順に番号を振って、A,Bの合計を求めるだけ。
答えは③
[2]
(Aの順位和)≦7 となる組み合わせは、
(1,2,3),(1,2,4)番目の値がA群に含まれているときの2通り。
$$順位の組み合わせの総数は、_6C_3(=20)通りなので、$$
片側P値は、
$$\frac{2}{_6C_3}=\frac{1}{10}$$
答えは②
[3]
Aに(1,2,3)番目が来る確率が0.03未満になる状況を選択肢から探ると、
$$\frac{1}{_6C_3}=\frac{1}{20}=0.1→ダメ$$
$$\frac{1}{_7C_3}=\frac{1}{35}\simeq 0.0286→OK$$
答えは②
問6 推定
[1]
(偏差値)=50+10×(標準化得点)
Aさんの標準化得点は、
$$\frac{X-\mu}{\sigma}=\frac{-1}{5}$$
よって、Aさんの偏差値は、
$$50+10\times \frac{-1}{5}=48$$
同様にして、Bさんの偏差値は70とわかる。
答えは③
[2]
受験者の人数比より、混合正規分布は、
$$\frac{200}{300}N(65,5^2)+\frac{100}{300}N(80,3^2)$$
$$\frac{2}{3}N(65,5^2)+\frac{1}{3}N(80,3^2)$$
係数の大きいほうの影響を強く受けるので、確率密度の山が高いのはN(65,25)の分布。
ここで、①か②に絞れるが分散を見比べると、文系の分布であるN(65,25)のほうが分散が大きいので裾の広い分布になっているはずであるので①は不適。
答えは②
[3]
再び標準化して上側確率を求める。
分布表より、
$$\Phi(1-\frac{60-65}{5})=0.8413\simeq 0.85$$
$$\Phi(1-\frac{60-80}{3})\simeq 1.0$$
つまり、文系の85%、理系の100%が合格しているので、
$$(合格率)=\frac{200\times 0.85+300\times 1.0}{300}=0.9$$
答えは④
問7 クラスター分析
[1]
これは覚えてなかったらoutなのである意味キツイ。
答えは④
②は最短距離法
③は最遠距離法
⑤はk-means(この場合は2-means)
※k-meansは非階層型クラスターにあたるので解答にはなりえないが……
[2]
表を見て際立っているのが「うに・いくら」の列。
$$\begin{pmatrix}2 \\5 \\5 \end{pmatrix}と(ア)が唯一小さい。$$
ここでデンドログラムをみればCとA,Bが遠く離れています。
この浮いているCが(ア)だろうな。とあたりをつけると選択肢が1つしか残りません。
答えは⑤
[3]
横軸が第一主成分、縦軸が第二主成分の値となっている。
表を見て、まず第一主成分得点が正のまぐろ、貝類、白身が右側に
次いで、第一主成分得点が負のサーモン、うに・いくらが左半分にあることがわかる。
この時点で選択肢が1つになる。
答えは④
問8 時系列解析
[1]
AR(1)で自己相関が0
$$\Leftrightarrow 1個前のデータ以外との相関はほぼ0。$$
条件に1番適しているのは②。
∵Lagが1の時以外は全部破線より小さい値になっているから。
あらためてLagが1の時の値を確認してみると0.5となっており、
$$\alpha=0.5という条件にも適している。$$
答えは②
[2]
$$u_tが定常なので、$$
$$V[u_{t+1}]=V[u_t]=\sigma_u^2$$
$$Leftrightarrow \sigma_u^2=\alpha^2\sigma_u^2+\sigma^2$$
α=0.1より、
$$\sigma_u^2=\frac{\sigma^2}{0.99}$$
答えは②
[3]
まず、標本平均はμの不偏推定量。(期待値をとってみてもいいが……)
$$V[\bar{X}]=\frac{\sigma_u^2}{10}$$
今度は偏自己相関が0じゃないので、
$$y_1,y_2,…y_Tはi.i.dじゃないことに注意して分散を求めると、$$
$$V[\bar{y_T}]=\frac{1}{T^2}V[\sum^T_{t=1}u_t]=\frac{\sigma_u^2}{T}+\frac{1}{T^2}\sum_{s\neq t}E[u_su_t]$$
$$\frac{\sigma_u^2}{T}の後ろは\alpha>0なので正の値$$
なので、T=10のときは、
$$V[\bar{X}]<V[\bar{Y_T}]$$
となっている。
以上より答えは③
問9 適合度検定
$$\chi^2=\sum\frac{(E_{ij}-O_{ij})^2}{E_{ij}}$$
なので、すべてのデータがa倍になると、
$$分子がa^2倍、分子がa倍になるので、\chi^2はa倍になる。$$
$$行数も列数も同じなのに\chi2は大きくなっているのでP-値は小さくなる。$$
全部の値をa倍したなら、標本サイズもa倍なので、
Vは「分子がa倍、分母がa倍」となり、結果的には変わらない。
問10 回帰分析
[1]
極端に0が多いのでスパース性(0が多いスッカスカ度合い)が高い(ウ)がラッソ回帰(L1正則化)。
(ア),(エ)が(イ)が変な形なのでOLSが入ってないんだろうということで(イ)がリッジ回帰。
OLSで(ア)の様にきれいにキレイに回帰直線にデータが乗っかるのは変なので(エ)がOLS、(ア)がOLS+AICと判断する。
答えは⑤
[2]
どんな本でもラッソ回帰は菱形、リッジ回帰は円の領域を持った図に見覚えがあると思う。
問題文から、α=1でラッソ回帰、α=0でリッジ回帰である。
グラフ上部の数字は係数が非ゼロの説明変数の数なので、これを見てみると、
αの値(ウ),(ア),(エ),(イ)の順に大きい。
答えは①
問11 因子分析
[1]
共通性が何なのか知ってないとムリ。
共通性をd、第一因子と第二因子の因子負荷量をそれぞれ
$$a_1,a_2とすると、$$
$$a_1^2+a_2^2=dなので、$$
答えは①
[2]
これまたバリマックスに関して正確な知識を持っていないとムリ。
分散が最大になるようにバリマックス回転を施せば、0と1に近辺に偏るようになる。
と覚えておく。
答えは④
[3]
Cは相対的に洗練度(横軸の値)が高いのでこれが違う。
答えは②
問12 時系列分析
[1]
プロットをみると、2017年から、数回前に一回だけ非常に大きな正の値をとって、それ以外は負の値なので、それを満たすコレログラムは⑤。
[2]
①:トレンド成分をみれば、記述の通り給与は増加傾向を示すが、2016年後半あたりから傾きが急激に緩やかなので正しい。
②:トレンド成分のメモリは12上昇している。単位が千円なので、12千=1.2万円で、この選択肢も正しい。
③:季節成分のグラフの山の数を数えると10個。期間は5年分なのでボーナスが2回というのは正しいと考えられる。
④:季節成分から、年間の山の頂点は大体200で、谷底は-50の値なので、
その差は250千円=25万円となり正しい。
⑤:これ、所見で解いたときはどちらかわかりませんでした。
以上から①~④が明らかに正しいので⑤が不適とわかる。
Appendixと参考文献
ノンパラメトリックやクラメールの連関係数の様なギョッとするような設問は見掛け倒しが多くて、丁寧に問題文を多そればとれることが多い。
推定や検定は統計検定2級の問題でたっぷり演習できるので問題ない。
その他では、
- 時系列解析
- 各種多変量解析法
- 機械学習
- 分散分析
がよく出る割には問題量が潤沢とは言えないので別途丁寧に対応すべき。
以下は参考書籍





